How we use Docker at the OPF
What we have seen so far
We have covered a lot of ground so far and have a good understanding of containers and images.
We have seen a little bit about ports and networking and a little bit of volumes. These are important concepts, so it is probably worth exploring these a bit further.
We also looked at how to take a base image 'off the shelf' and adapt it for our own use. This was achieved in a very manual way, so we can look at how to do this procedurally in a reproducible way.
Where can we go next
Applications in Production environments often need multiple containers to work together, for instance most interactive websites require a database at the very least and may have other dependencies too.
Up until this point we have been either using the command line or the desktop GUI tool to launch and manage our containers, this is great for testing and doing very specific Docker tasks, but can become cumbersome for server deployments with many Applications, where each application is composed of multiple containers.
Ideally we would like to be able to manage a lot of containers in a structured way, that is reproducible and perhaps we can manage via git (and by extension store in GitHub). Today we are going to try to get there.
Networking
I kind of glossed over this Docker fundamental concept so far (but if you are into networking and want a deep dive, the official docs are very informative). If we just have the host PC and a single test container then there is very little to speak about other than opening a port into the container so that the host PC can interact with the application. Our example used a web server - so interaction was as simple as loading a browser. Some applications like databases or APIs might require more complex testing tools, and some containers are designed to have no networking and you interact with via the command line. When you start a container and open a port Docker will create a subnet for that container, give it its own IP address and the container will be isolated from other containers and the outside world via NAT and DNS. If you are unfamiliar with these concepts I don't want to go down those rabbit holes in this discussion. But these are the same tools your home router uses to let your PC communicate across the internet, but stops other customers from your ISP or the wider world sending documents to your printer or connecting to your smart speakers. Docker will create lots of virtual and separate networks for the containers you deploy. Docker will also automatically destroy these networks when they are no longer needed, unless you specify them.
Going back to our example application with a web-application and database. It will be necessary for these two containers to be in the same network. We can create a bridge network give it a name, then we can start both our containers and add them to the network. At this point they can use their respective hostnames (we didn't cover this yet, but you can specify a container's hostname with a --hostname flag) to communicate within the network (using DNS services) and communicate with the outside world via NAT provided by the Docker engine.
There is more to read up on this subject like network drivers and other advanced setups, but for our needs we have enough, but I would like to address ports in a bit more depth.
Ports
Just a quick recap on ports with our new knowledge.
Exposing ports from a container to the host is done with the -p flag like so
-p 80:80
This is a port mapping with the Host port on the left and the container's port inside the network on the right:
-p HOST:CONTAINER
This ability to map ports is powerful because it means containers can have the same ports in use inside their own networks, like this port 80 above is the standard HTTP web port, so I might have a lot of web servers all using port 80 inside containers - but i can expose them all to my host via a range of ports I have on my host machine (say 80, 81, 82, 83, 84, and 85).
This is useful for testing, but in production we should try to map as few ports as possible for security reasons. The port to my database container does not need to be mapped for my web-application to communicate with the database inside the bridged network for instance.
Volumes
Volumes have a similar flag construct to ports:
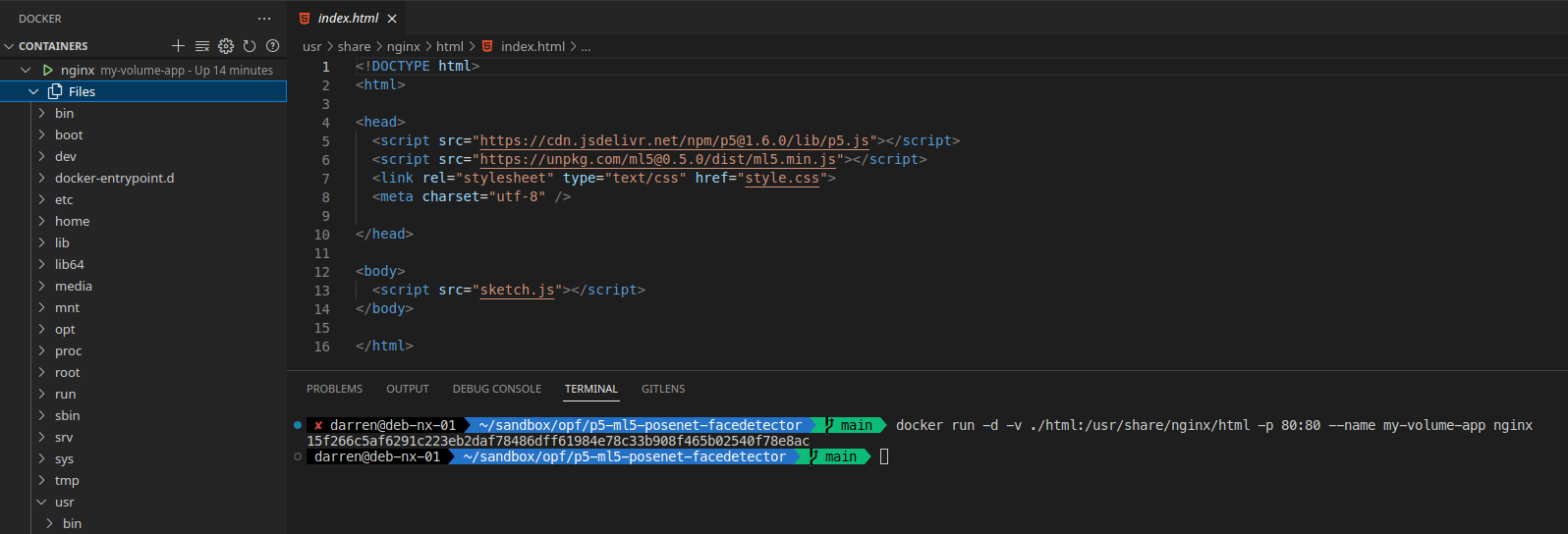
-v ./files/:/opt/app/files/
-v HOST_PATH:CONTAINER_PATH
This lets you inject folders or single files into the containers file system overwriting the files provided by the source Image. They also allow you to persist files in the Host that would otherwise be lost when the Container is recycled. Again there is more to Storage in Docker than just volumes, and I encourage you to explore the official documentation if you are interested.
Bringing it all together
Once you get the docker bug it wont be long before you find yourself with 20 or so containers all running at once and it can get a bit overwhelming.
While it is not impossible to manage a lot of containers with just the command line, I personally prefer to use some ease of life tools to help. The first two are text files that help us organise our Images and Containers. They are the Dockerfile and docker-compose.yml files. With these files we can manage our servers, and use git to help us. This is a concept know as Infrastructure as a service. We can manage our servers like a git project, and quickly redeploy applications or migrate them in a controllable repeatable way.
Dockerfile
In part two we saw how to take a base Image and tweak it to our needs by pulling the image from DockerHub and then making changes and tweaks to it, and then create a new image from that. These Images can then be pushed back to DockerHub if you have an account.
A Dockerfile is a text file with a set of instructions that enable the creation of an Image in an automated fashion. The commands in the Dockerfile are the same as you would use on the command line. Plus you can use the RUN command to execute shell commands inside the new Image.
docker-compose.yml
When we start to have a lot of containers especially when there are interdependencies - like a web server needing a database container, using the command line to orchestrate all of these containers their networking and volumes can be cumbersome. So one way to address this is with a 'compose file' - this is a text file that uses a human readable structure to define our application stack and we can pass it to docker to start and stop the entire application stack at once. It provides a clear and concise way to specify the services, networks, volumes, and other settings required for running interconnected containers as a cohesive application stack. Within the docker-compose.yml file, you can define various services and their corresponding images, along with their dependencies, environment variables, exposed ports, and more. By using this file, developers can easily orchestrate the deployment and scaling of complex applications with a single command, simplifying the process of managing and maintaining multi-container environments. This information being in a text file means we can check it into git so we get all the benefits of change control over infrastructure deployment too.
Part 4
In the next part I will show some real world examples of these deployments.